


Destination Benchmarks
JetBackup 5.1.x introduces a new proprietary backup engine with a smart indexing system that allows JetBackup to track changes locally. At this time, the new backup engine is used exclusively on S3 compatible destinations but will eventually roll out to all other supported destination types, converting the current ones to legacy.
As part of the new engine onboarding procedure, we gathered some benchmarking statistics and decided to share them with the community as it seems there is a lot of interest and questions about it. The results shown are based on rsync-over-ssh destinations and S3 compatible destinations.
S3 Incremental Pipeline
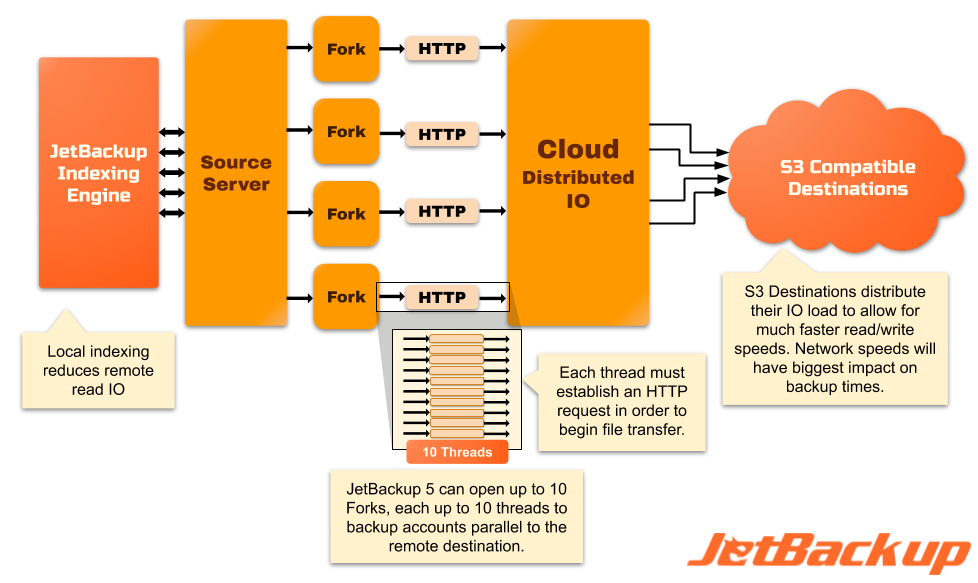
Diagram A: The new JetBackup 5 engine manages backup-indexing locally, avoiding the need to scan & compare data to the remote destination before backup transfer. It allows JetBackup to solely use remote IO during the backup transfer process – during writes, not reads. After the new engine completes indexing, the backup process begins transferring changes from each account to the destination. The backup engine opens a fork with ten threads for each account backup getting processed. Each Thread will then fulfill an HTTP authentication request then transfer the objects to the destination over the provider’s cloud infrastructure, effectively distributing the IO and likely limiting potential bottlenecks to Network Download/Upload Speeds.
SSH Pipeline
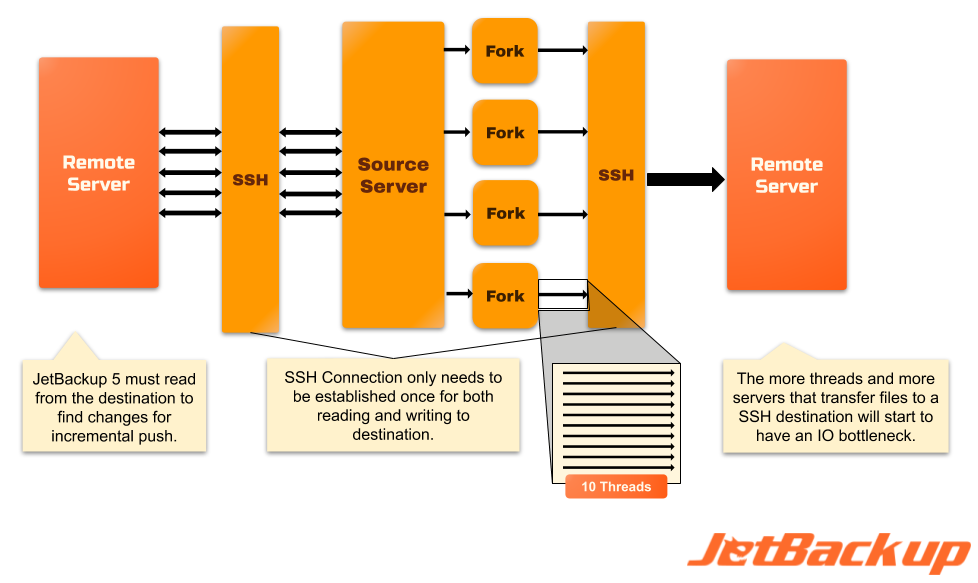
Diagram B: JetBackup 5 does not currently use the new indexing engine for incremental backups to SSH destinations but utilizes Rsync-over-ssh instead to read all the files from the destination server to compare changes with the local server. This process generates high read IO on the remote server before starting the backup process. As with the S3 pipeline above, JetBackup can still create up to 10 forks to backup up to 10 accounts in parallel. But unlike S3 destinations, SSH destinations only require a single connection opened to begin data transfer. However, SSH Destinations will most likely reach an IO bottleneck as more files get written to the remote server.
Running the Tests
First run
On the first run, it is unfair to compare S3 to Rsync-over-SSH. S3 compatible destinations are sending files over HTTP requests. This process will be utilizing more resources for opening/closing requests.
Let’s say that a file is represented by a single HTTP request (open connection + authentication). Let’s assume this whole process will take about 1 second. With 100 files to send over, we can assume that only the connection part will take us about 100 seconds, and that is, without the time it took to push the file over.
On the other hand, with rsync-over-ssh destinations, we will open the connection only once (that 1 second used as an example) just to open a tunnel. Once the tunnel is open, there is no need for further authentication and we can start sending files.
Given the above, we can say that using rsync-over-ssh for the initial run will most likely be faster than doing the initial run to an S3 compatible destination.
We can narrow the gap by changing the Concurrent Backup Tasks Setting. This setting will allow you to backup multiple accounts in parallel to destinations by opening an additional max of 10 Forks with up to 10 threads each to transfer files. Although it may not be faster than SSH initially, it will reduce the difference substantially.
Second run and beyond
For both destinations, the second run should be much faster as we will only send changes.
The results here might dramatically change in the “real-life scenario” where you will most likely share a rsync-over-ssh destination with several other servers.
Rsync will scan both the entire source & destination while comparing changes causing a dramatic drop in IO read performance on the remote server itself. Performance tweaking like SSD Cache will not take effect here. With 100 servers backing up to the same destination, you will most likely see a crucial performance downgrade just while comparing source and backup destination before even starting to send over the changes.
With S3 compatible destinations in most cases and with respectable providers, there should not be an IO bottleneck as most of the providers are distributing the load in their cloud. The bottleneck will instead likely be with Network Download/Upload Speeds.
Additionally, JetBackup’s engine is indexing internally, avoiding the need to scan & compare the remote destination. We will only use remote IO during a backup process – to write, not to read.
Comparing the destinations, using the “real-life scenario” mentioned previously in a shared rsync-over-ssh environment, the timing will fluctuate based on the load and active clients on the server. With S3 compatible destinations, that timing was always consistent without considerable changes (1 – 2 minutes gap). Furthermore, using a shared environment destination in both cases – S3 was much faster.
In the same test, in a lab environment, where the rsync-over-ssh destination is not shared with anyone and used on only one server, rsync will be slightly faster or the same as S3.
Conclusions
These conclusions were made from running multiple tests on our internal servers. Results may vary depending on different configurations.
- Case 1: Multiple servers backing up to shared destination
The new indexing engine with S3 destinations will give this destination a much better performance rating after the initial run compared to rsync-over-ssh destinations. This is due to the IO bottleneck a single destination remote server will have during file transfer, and the need for rsync to read from the destination when comparing changes.
- Case 2: Single server backing up to a non-shared destination
In this case, SSH destinations will have a slight edge or be on par with S3. The IO bottleneck will not affect the speeds of the SSH Incremental runs drastically. The single source server will have exclusive access to the remote server’s IO. After the initial runs, both destinations will backup accounts in roughly the same amount of time. SSH will be faster if their IO limits are higher than the Network limits for S3.



{kind=link}
{kind=link}
{kind=link}